
클러스터 구성을 할 수 있는 분산 애플리케이션의 한 종류인 카프카(Kafka)는 클러스터를 구성하는 서버 대수를 정해야 합니다.
주키퍼와 분산 애플리케이션 면에서는 동일하지만 클러스터가 운영되는 방식은 다릅니다.
과반 수 방식으로 운영되어 홀수로 서버를 구성해야 하는 주키퍼와 다르게, 카프카 클러스터는 홀수 운영 구성을 하지 않아도 됩니다.
본 포스트에서는 카프카 클러스터의 브로커 수를 3대로 구성하겠습니다.
간혹 카프카와 주키퍼를 동일한 서버에 같이 오려려서 운영하는 분들도 있는 소규모 환경이라면 괜찮을 수도 있겠지만 대규모로 카프카를 운영하는 환경에서는 좋은 방법이 아닙니다.
설치 환경
Ubuntu 18.04.5 LTS카프카 다운로드
카프카 최신 버전 다운로드를 위해서 아파치 카프카 페이지로 이동 ( https://kafka.apache.org/downloads )
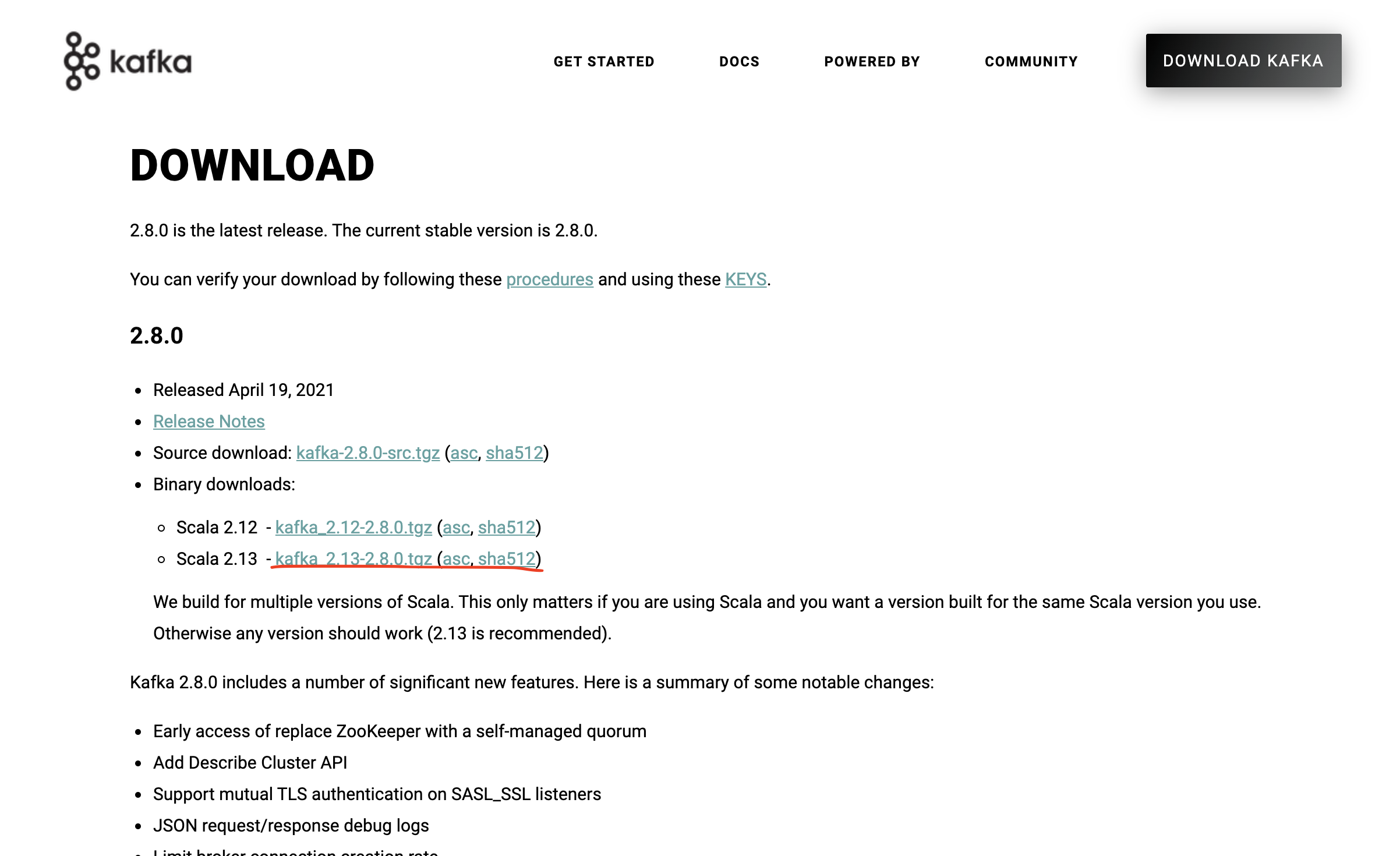
해당 페이지에 접속하여 kafka 2.13-2.8 version을 다운로드 하겠습니다.
링크를 클릭하게 되면

위와 같은 페이지가 나오게 됩니다.
이제 리눅스 서버에 다운로드하기 위해서 링크 주소 복사를 합니다.
이제 리눅스 서버로 넘어갑니다.
## 이동하기
## 해당 경로는 다른 경로로 변경해 설치해도 됩니다.
cd /user/local
## 카프카 다운로드하기
wget https://mirror.navercorp.com/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz
## 카프카 압축해제
tar zxf kafka_2.13-2.8.0.tgz
압축을 풀게 되면 해당 경로에 kafka_2.13-2.8.0라는 폴더를 확인할 수 있습니다.
이 폴더를 kafka라는 이름의 심볼릭 링크를 생성합니다.
## 심볼릭 링크 생성
ln -s kafka_2.13-2.8.0 kafka
## 심볼릭 링크 생성 확인
ls -la kafka
-> lrwxrwxrwx 1 root root 16 6월 9 20:05 kafka -> kafka_2.13-2.8.0
카프카 환경설정
환경설정에 필요한 정보인 서버별 브로커 아이디, 카프카 저장 디렉토리, 주키퍼 정보를 정해야 합니다.
- 서버별 브로커 아이디
| 카프카 호스트 이름 | 브로커 아이디 |
| peter-kafka001 peter-kafka002 peter-kafka003 |
broker.id = 1 broker.id = 2 broker.id = 3 |
위의 테이블처럼 임의로 카프카 호스트 이름과 브로커 아이디를 정합니다.
- 카프카 저장 디렉토리
카프카는 일반 메시지 큐서비스들과 달리 컨슈머가 메시지를 가져가더라도 저장된 데이터를 임시로 보관하는 기능이 존재합니다.
준비한 서버의 디스크에 따라 여러 디렉토리를 만들어 구성할 수 있습니다.
여기서는 2개의 데이터 저장 디렉토리를 만들고 설정하도록 하겠습니다.
## 데이터 저장 디렉토리 1
mkdir -p /data1
## 데이터 저장 디렉토리 2
mkdir -p /data2
- 주키퍼 정보
카프카의 주키퍼 설정 정보 입력 시 주키퍼 서버 전체 리스트가 아닌 주키퍼 서버 1대의 정보만 입력한 경우는 매우 위험한 설정입니다.
예를 들어 하나의 주키퍼를 3개의 카프카 클러스터에 설정하는 경우 주키퍼가 다운된 경우 3개의 카프카 클러스터가 죽는 현상이 발생되기 때문입니다.
그래서 이런 예기치 않는 현상을 막기 위해서는 각 카프카 클러스터에 주키퍼 앙상블 서버 리스트 모두를 입력해야 합니다.
## 주키퍼 앙상블 서버 리스트 입력
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181
하지만 주키퍼 앙상블의 호스트 이름과 포트 정보만 입력하면 주키퍼 지노도의 최상위 경로를 사용하게 됩니다.
이렇게 최상위 경로를 사용하게 되면, 하나의 주키퍼 앙상블 세트와 하나의 애플리케이션만 사용할 수 있게 됩니다.
그 이유는 서로 다른 애플리케이션에서 동일한 지노드를 사용하게 될 경우 데이터 충돌이 발생할 수 있기 때문입니다.
이 방법이 잘못된 방법은 아니지만, 약간의 설정을 변경해 하나의 주키퍼 앙상블 세트를 여러 개의 애플리케이션에서 공용으로 사용할 수 있는 방법이 있습니다.
그 방법은 지노드를 구분해서 사용하는 방법입니다.
## 지노드 구분 1번방법
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181 / peter-kafka001
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181 / peter-kafka002
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181 / peter-kafka003
## 지노드 구분 2번방법
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181 / peter-kafka / 01
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181 / peter-kafka / 01
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181 / peter-kafka / 01
지노드를 구분하는 방법을 사용하게 되면 주키퍼 앙상블 한 세트로 여러 개의 애플리케이션을 사용할 수 있습니다.
이제 환경 설정 파일 수정을 위한 사전 작업은 끝났습니다.
## 카프카 환경설정 server.properties 파일
vi /usr/local/kafka/config/server.properties
해당 파일을 열면 아래와 같이 나온다.
우리는 여기서 브러커 아이디, 데이터 저장 디렉토리, 주키퍼 정보를 수정합니다.
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
"""
peter-kafka001
broker.id=1
peter-kafka002
broker.id=2
peter-kafka003
broker.id=3
"""
.. 생략 ..
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
"""
log.dirs=/data1, /data2
"""
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
.. 생략 ..
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
"""
zookeeper.connect = peter-zk001:2181, peter-zk002:2181, peter-zk003:2181 / peter-kafka
"""
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
.. 생략 ..
- 준비한 서버에 맞는 브로커 아이디(broker.id)로 매핑한 숫자로 변경합니다. (""" ~~ """ 부분)
- 데이터 저장 디렉토리 수정은 log.dirs라는 부분을 다음과 같이 변경합니다. (""" ~~ """ 부분)
- 주키퍼 정보 수정은 zookeeper.connect 부분을 다음과 같이 변경합니다. (""" ~~ """ 부분)
카프카 실행
준비한 카프카의 모든 서버에서 환경설정 수정이 완료되었다면 실행해 보겠습니다.
카프카에서 제공하는 명령어를 이용할 수 있습니다.
명령어 설치경로인 /usr/local/kafka 하위 경로인 bin 디렉토리 밑에 위치하고 있으며, kafka-server-start.sh입니다.
시작명령어와 카프카 환경 설정 파일을 옵션으로 주어 실행하면 됩니다.
## 카프카 실행
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
위의 사진은 실제 실행한 화면입니다. 이렇게 백그라운드로 돌리지 않으면 출력화면이 지속됩니다. (Ctrl + C : 종료)
또한 셸이 강제 중지되면 해당 셸에서 실행한 프로그램도 같이 종료되기 때문에 반디시 백그라운드로 실행해야 합니다.
## 카프카 실행 1 (백그라운드)
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties -daemon
## 카프카 실행 2 (백그라운드)
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
카프카 서비스를 중지할 수 있는 명령어는 시작 명령어와 동일한 경로에 위치하고 있습니다.
## 카프카 서비스 종료
/usr/local/kafka/bin/kafka-server-stop.sh
[부록] systemd 서비스 등록
주키퍼와 동일하게 운영 편의성 등을 위해서 카프카도 systemd에 등록하겠습니다.
이름은 kafka-server.service로 지정하겠습니다.
## systemd 파일 설정
vi /etc/systemd/system/kafka-server.service아래와 같이 설정합니다.
[Unit]
Description = kafka-server
After = network.target
[Service]
Type = simple
User = root
Group = root
SyslogIdentifier = kafka-server
WorkingDirectory = /usr/local/kafka
Restart = no
RestartSec = 0s
ExecStart = /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop = /usr/local/kafka/bin/kafka-server-stop.sh
설정 후 반드시 systemd 재시작해야 합니다.
## systemd 재시작
systemctl daemon-reload
만약 systemd를 설정하게 되면 앞으로 카프카 서비스를 실행하기 위해서는 아래와 같은 명령어로 실행합니다.
## systemd로 실행
systemctl start kafka-server.service
카프카 서비스 상태 정보를 보는 방법은 아래와 같은 명령어로 실행합니다.
## 카프카 서비스 상태 확인
systemctl status kafka-server.service